
Like many other companies today, we work with the Scrum framework at G DATA to develop software where many teams use story points to estimate the work, complexity and risk of backlog items. This post discusses an idea how to use story point estimations to estimates the costs of a project or more precise, an epic. This eradicates the need for time tracking on issues, which gives the developers more time to focus on what matters. Furthermore the approach presented here is fully automatable which guarantees up-to-date budget numbers.
In the proposed approach below, we presume a knowledge on Scrum and Agile development methods by the reader. If you are not familiar with the topic, we recommend to read up on Scrum, Agile, Story Point based estimations and typical issue types used to organize a Scrum backlog, before reading the article.
Why compute costs?
Before we jump right into story point based cost estimations, lets recall, why we want to estimate project costs at all. Scrum is about Evidence-Based Management. This means that decisions should be based on evidence like usage metrics, cost estimations, expected ROI and so on, instead on gut feeling.
Estimating the gain of a new feature or project is much easier, if we have gathered data from the past to compare the new feature or project to. For example, imagine a new feature should be added and the feature size is roughly half the size of the last feature implemented. If the time and costs needed for the last project are known, the estimation for the new feature would be the half time and costs from the last feature. Thus, gathered evidence from the past allows us a better estimation of the future. With this knowledge, the most important questions before starting any new project can be answered: Should we do it at all? If the expected ROI is smaller than the estimated costs, maybe another feature should be implemented instead.
While the last passage explained how cost estimations from the past can help to estimate the future, gathering evidence while the project is under development and after release is even more important. Computing the costs of a project under development helps to check if the first estimation and acquired budget is sufficient or if less important features have to be left out to reach the project goal on budget. After the release, the running expenses for the project in sum with the initial build costs have to be compared to the ROI. This allows to decide if a project was a success and should continue, or if the more economical solution would be to end the project. Keep in mind that the success does not have to be measured in monetary value but could, for example, consist of a reduction in technical debt or be a strategic investment.
Key-Objectives for the cost estimation
We identified three key objectives for cost estimations in our team:
- The costs have to be transparent for everyone to see
- Costs have to be computed automatically and frequently
- The calculation has to be comprehensible and reproducible
The first requirement ensures that everyone involved in the project understands the reason behind decisions based on costs and provides the possibility for everyone to optimize costs in their domain of the project. The second requirement guarantees that all cost estimations are always up-to-date and cannot be forgotten to be updated. The last requirement ensures trust in the cost estimation, because everybody can re-calculate them and check the results. Furthermore, the reliability of the cost estimations is improved, because errors in the calculation will be found faster, if multiple people checked the correctness.
Requirements for cost estimations
The technical requirements are all given through access to our digital Scrum board which provides us with the needed information to compute project costs:
- Number of story points for a backlog item
- Relations between the backlog items (e.g. to which epic they belong)
- Velocity of past sprints and therefore an average velocity
- Timeframe of the sprint (2 weeks)
To compute the costs for a project, based on the information from the Scrum board, we need to know two more things.
- Number of developers in the team
- Average salary per hour for the team from the company's perspective
To keep the article short and focused on Story Point based cost estimations, other costs like hardware, licenses, office equipment and so on, are not taken into account. Instead, the focus will be on developer costs based on the time and effort put into the project.
Story point based cost estimation
From all backlog items, the Epic is the most interesting in our use case, because we try to model features into epics. One epic or the sum of a few epics are the whole project costs. If your backlog model looks a bit different, the formula introduced below is pretty easy to adapt. If you are not familiar with story point based estimations, have a look at What are story points and Three reasons to estimate with story point.
The formula to estimate the costs for an epic is:
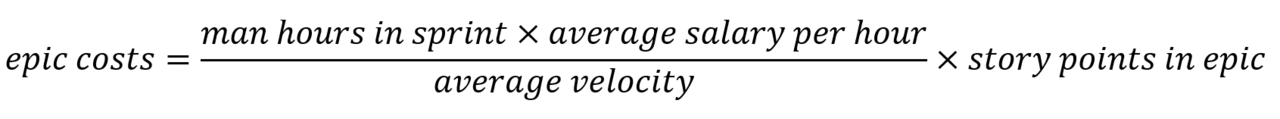
First, we compute the costs of one story point. This is done by multiplying the number of man-hours in a sprint with the average salary per hour, which corresponds to the total costs of a sprint. Then we divide this by the average velocity of the last few sprints, which gives us the costs of one story point. Important here is that we only take the last few sprints to calculate the velocity because the average velocity tends to change over time. To get the final costs of an epic, we multiply the number of story points in an epic with the costs of one story point.
Lets play this through with a toy example - note that the following numbers are for demonstration purposes only. Imagine we want to compute the costs for the epic "Super Feature", which is distributed over two sprints.
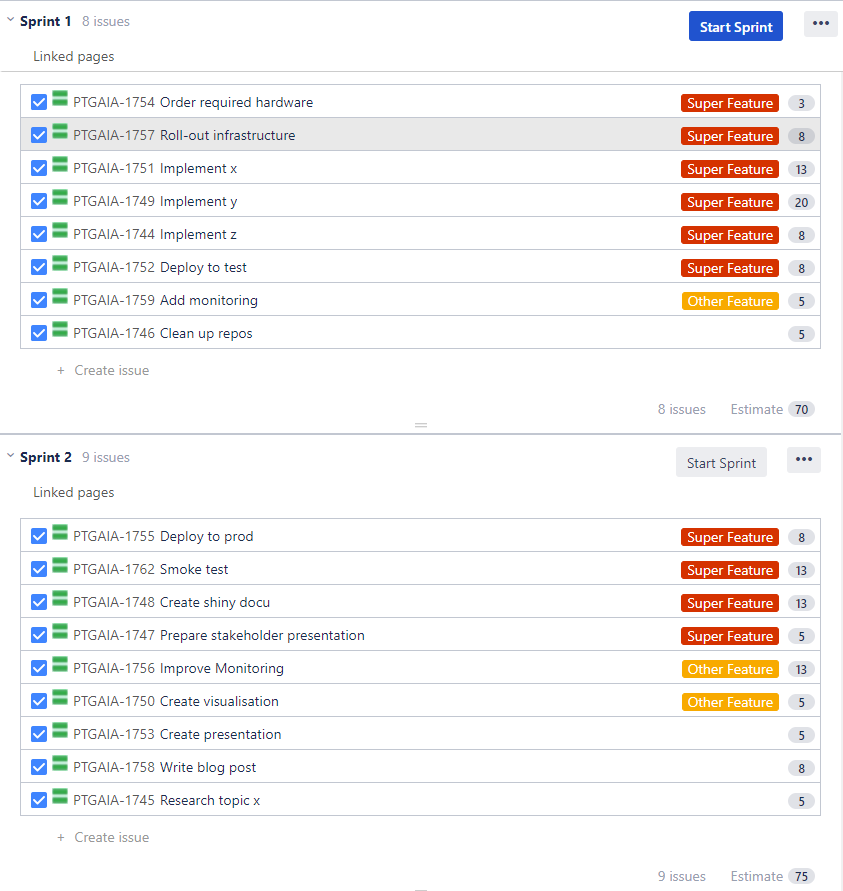
To compute the costs for that epic we need a bit more information which is given in the table below. The numbers are just some random example numbers and do not represent a real development team at G DATA.
| Number of developers | 4 |
| Weeks per sprint | 2 (40h/week) |
| Average salary per hour | 35€ |
| Average velocity | 72 |
| Story points in epic "Super Feature" | 99 |
If we use the formula from above and insert all the values we get the costs for the "super feature" epic.
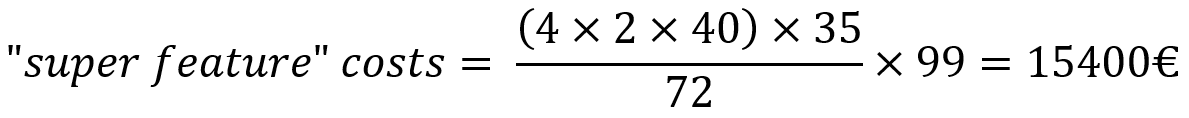
The costs for the epic "super feature" are estimated at 15400€. Keep in mind that this number only reflects direct development costs. Other costs, like hardware, licenses or the planning of the epic itself are not part of the equation. This means that the costs computed here are only a lower bound and the additional costs should be added to get a more precise result.
Conclusion
In this post, we have presented an idea, on how to estimate feature or project costs based on story point estimations instead on time estimations. The advantage of story point-based costs estimations is that they are much easier than time-based estimations. For time-based estimations, every issue has to be tracked, which means that if a developer starts working at the issue, he has to start the tracking, and if he stops working at the issue, he has to stop the time tracking. If a developer has multiple context switches each day or works in pair programming with different colleagues, tracking the exact time spend on an issue is nearly impossible. On the other side, the story point estimations are an abstraction of the work that has to be done in a hard time box (the sprint). It doesn't matter if all developers worked on one issue for the whole sprint sitting side-by-side or if they all worked independently of each other on multiple small tasks. As long as the average velocity stay largely the same, the costs are for one story point stay the same. This allows an easy computation of costs for any kind of issues.
The approach shown here is an experimental stage for us. We hope to improve it in the future to get more precise results and to automatically add non-developer costs to the estimations. If the approach feels stable enough for us, we will publish a new blog post with the updates and most likely publish the source code for the automation.