

Website operators want real visitors on their websites. They also do not want an overload attack to bring the website to its knees. Captchas are an important tool for this - small picture puzzles that a human being can easily solve, but which give machines a headache.
The dark side of Machine Learning
A research team has now succeeded in using machine learning to automatically solve some of the common text-based Captchas. The attack model requires little effort. This makes the advantages of these Captchas obsolete. In contrast to earlier models, the newly developed model requires only little data to learn effectively. According to a report by Science Daily (link will open in a new tab), the model only needs about 500 Captchas to learn how to solve them.
This is worrying because many websites rely on captchas to protect themselves from overload attacks. If an attacker has access to this technology, he can easily overcome the hurdle that a text Captcha puts in the way of a visitor and still overload the page. Up to now, programming a captcha solver used to be very time-consuming. A lot of manual work and hundreds of thousands of data records were required. To top it all off, a Captcha solver could - until now - only be trained for a very specific type of Captcha. For this reason, criminals have done the most obvious thing in the past: they have looked for other people to solve the Captcha for them. By enlisting low-wage workers, thousands of Captchas could be solved per hour. According to an estimate in another research report (PDF file opens in a new window), criminals could sometimes have 1000 different Captchas solved for about a dollar.
This enabled not only DDoS attacks, but also the sending of spam messages.
What is a Captcha?
"Captcha" is the abbreviation for Completely Automated Public Turing test to tell Computers and Humans Apart. Originally, the Turing test is designed to tell a human being whether he is dealing with a computer or a human being - so strictly speaking, a captcha is a reverse Turing test: a computer gives a human being a task that, due to its nature, cannot be solved by a computer. One of the most common of these tests consists of an optically distorted sequence of letters, sometimes placed against a different colored background. The user must specify the correct sequence of letters. If the user manages to do this, the test is passed because the model assumes that only one person can successfully complete the test. This fact is used to distinguish legitimate visitors to a website from automated visits, for example triggered by a botnet. Other types of captchas work with images, in which, for example, the user must identify those images from a series that contain certain items.
A clear vision
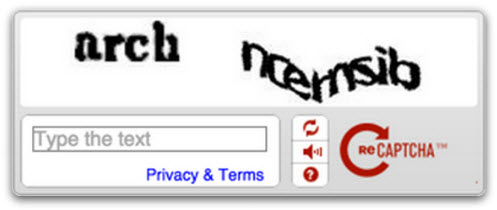
Meanwhile, no one should be surprised that machine learning is not only an invaluable tool in the fight against online crime and in the detection of malware, but also one that criminals can make use of. One of the researchers has already gone so far as to say that website operators should no longer use captchas based on the research results and advises on other alternatives such as the analysis of user behavior or a device's location.
At present, however, the attack only works against text-based captchas - that is, wherever images are used, for example "Select all images that show a car", the attack has no chance of success - yet