
What's Phishing?

Phishing is a cyber crime where cyber criminals lure internet users on websites which look confusingly similar to popular websites like Paypal or Facebook. There are also phishing websites which aren't visual distinguishable from these websites. The victim thinks it is visiting the real website and enters confidential information like passwords or credit card information in order to log on to a website or to complete account information. As a result the personal information falls into the hands of the cyber criminals who host the phishing website. Often, the stolen information is used for further attacks or other criminal activities.
Phishing is not only the most used but also the most successful attack applied by cyber criminals [1][2]. Phishing causes enormous financial damage to businesses and private persons [3]. The theft of company secrets (e.g. customer data, ideas/concepts or patents which are not registered at that time) poses a significant threat to the economic success of a business company. The theft of customer data is likely to result in an enormous loss of image for the businesses. Attacking private persons, the stolen data is often used to realize complete identity thefts. Applying identity thefts, cybercriminals impersonate their victims and perform actions outside their authorization as for example make purchases in the name of the victim or commit further cyber crime while using the hacked PC of the deceived person. More and more frequently, cyber criminals manage to steal passwords of cloud providers like AWS or Azure and are thus able to use the computational power for criminal purposes.
Identity theft causes a huge bureaucratic effort of reverting the executed actions of the cyber criminals. Even worse than all the bureaucratic effort are the legal consequences that apply to the person concerned. The victim who owns the hacked PC or server can be held liable for the criminal actions which are executed from the victims machine.
| https://johndoe:mypassword@www.example.com:80/file1/index.html?birthdate=04091992#Article2 |
Username and Password: These components are optional and allow the website visitor to log on to certain websites by just entering the URL. The username is separated from the password by the reserved sign “:”. The hostname is separated from the password with an @-sign.
Hostname: The hostname defines the server name on which the website is made available for download. The hostname is either written in a readable sequence of letters (e.g www.gdata.de) or as a numerical IP-address (e.g. 212.23.136.50). Every readable domain name gets resolved to a corresponding IP-address, which is then used for the connection establishment. This is why every website is also accessible by entering the corresponding IP-address in the browser bar.
Port: The port immobilizes the application on the server to which a connection should be established. The application which is responsible to deliver the website to the visitor runs on port 80 by default considering HTTP or on port 443 considering HTTPS. The port number is optional and the above mentioned standard ports are automatically appended to the URL. The port number is separated by a “:” sign from the hostname.
Path and Filename: Because websites are composed of several documents/sites, most website developer organize these documents in different directories. This is done to provide a better overview and structure. By entering the path and the file name, the visitor of the website specifies which website he wants to request or view.
Query: With the help of the query, user input which is entered on the website can be send to the server for further processing. In the example URL above, an entered date of birth is send to the server. The query is separated from the rest of the URL by a question mark. The query consists of a identifier and is followed by a value separated by a “=” sign. If necessary further identifier-value pairs are added with a “&” separator.
Fragment: The fragment is used to tell the browser to automatically scroll to a sepecific part of the website, in our example to article 2. The fragment is separated from the rest of the URL by a #-sign.
Phishing Strategies – The tricks of cybercriminals
All phishing attacks have one thing in common, the victim must be encouraged to click on a phishing URL. Therefore the cyber criminals use several tricks to let the victim believe that the URL is the address of a trustworthy, popular website. Therefore the cyber criminals use tricks to obfuscate the difference between the real URL and the phishing URL. Let's take the three URLs below as an example. Do you recognize the difference between them?
1. Mixed-script Spoofing with unusual character sets
| Original URL | http://www.google.com | U+006F, small o from the ASCII-Set |
| Phishing URL | http://www.gооgle.com | U+043E, small o from the Cyrillic alphabet |
| Phishing URL | http://www.gοοgle.com | U+03BF, small Omicron from the Greek alphabet |
Probably you recognize a small difference between the second and the third URL, if you take a closer look at the character 'o'. But would you spot this difference if you are unsuspectingly browsing? Probably not. Additionally the first and the second URL are practically not distinguishable. Considering this type of phishing, cybercriminals exploit the possibility to use different font families in the URL. These font families plot the same characters in slightly different ways. In the example above, the letter 'o' is illustrated using the latin font family, the cyrillic and the greek font family.
2. Inserting invisible characters
Invisible character injection makes use of invisible unicode characters. Inserting those characters into a URL, the visible text is not distinguishable from the original URL.
3. Bidirectional Text Spoofing
Bidirectional Text Spoofing exploits Unicode scripts that show a right-to-left writing direction in order to mix them up with normal left-to-right writing scripts. After the browser renders these combined scripts, the resulting URL characters appears in a different order.[21] After rendering, this can lead to bidirectional URLs which are undistinguishable from left-to-right orientated URLs.
4. Friendly Login URL
| http://paypal.com:login@phishingsite.org |
Another phishing strategy to deceive the recipient of the phishing URL, is the use of so-called Friendly Login URLs. Would you fell for this phishing attack? Friendly Login URLs are URLs which are present in the following format: schema://username:password@hostname/path and allow the website visitor to log on to certain websites by just entering the URL as already described in the section about URL structure. The user therefore does not need to enter his access information on the website itself. The server extracts the username and password out of the URL and verifies the password for correctness. In the example above, phishingsite.org (marked red in the figure above) is the URL if no login data is sent to the server. Prefixing “paypal.com” as a username and “login” as a password, the victim is tricked into thinking the login data is the actual domain name paypal.com/login.
5. Names placed in Subdomain
| http://paypal.login.30jka.sde{...}ajd.233.phishingsite.org |
This phishing strategy exploits the fact that most people read from left-to-right, whereas the resolving of the URL happens from right-to-left. Cybercriminals insert the names of the imitated websites into the URL as subdomains as you can see in the example above. By adding arbitrary character strings in the form of subdomains to the URL, the real identity of the server (“phishingsite.org” in our case) gets arranged at the end of the victims browser address bar and is therefore out of focus. The website visitor just reads the name of the imitated website (“paypal.login” in our case).
6. IP-address and Hostname in the Path
| http://141.255.145.23/www.paypal.com |
Often the hostname of a phishing URL is obfuscated with its corresponding IP-address. The imitated URL is placed in the path of the URL.
7. Typos and similar Letters
| Orginal URL: | http://www.paypal.com |
| Phishing URL: | http://www.paypaI.com |
In this case, the large letter i (I) is used instead of the small letter L (l) at the end of the URL www.paypal.de. The URL is misspelled purposely. Characters are replaced by characters which are similar in terms of visual appearance.
8. Shortened URLs
| http://goo.gl/nbKckE |
URL shortening services do not just decrease the length of the original URL, but also create a new URL, which consist of a service sitename (e.g. bit.ly or goo.gl) and a random sequence of letters and numbers. By just looking at the shortened URL, the visitor of the website is not able to identify the website to which he is redirected after clicking on the shortened URL. Therefore the identity of the attackers website is obfuscated.
9. Encoded URL Obfuscation
| Dword | http://3515261219 |
| Octal | http://0321.0206.0241.0043 |
| Hexadecimal | http://0xD186A123 |
Usually IP-addresses are written as blocks of four (Ipv4) or six (Ipv6) digits/characters. Additionally to this way of writing IP-addresses, they can also be represented using a hexadecimal-, octal- or hexadecimal notation. Website operators use this representation in order to hide the written-out name (hostname) of the website.
10. Domain Shadowing
Beside the strategy of hacking another webserver and afterwards compromising it and using the mentioned obfuscation techniques to hide the Second-Level-Domain, there exist the strategy to use the good reputation of the Second-Level-Domain. Using this technique which is called Domain Shadowing, cyber criminals gain access to the DNS management account of the page owner and add subdomains which lead to the IP adresses belonging to themselves. Using this approach, the webserver itself is not hacked. Only the DNS record belonging to the webserver is compromised. The key advantage of the Domain Shadowing technique is that it takes notably more time to detect the existence of the phishing website and to remove it. This is due to the fact that there don't exist any indications of the attack on the webserver. Additionally, thorough collaberation with the registrar and/or DNS operator is needed to ensure that the original website is not influenced by phishing.
11. Serious-Sounding Keywords
| http://secure-login-paypal.com |
In order to try to gain the victim's trust, serious-sounding keywords are used in the URL and combined with the target organization. In the example above, a revisal of the WHOIS-data can be used to figure out if the domain is registered by Paypal or not.
Machine Learning
People who thoroughly check the URLs before clicking on them could recognize some tricks of deception. But because it is human that we are often in a hurry or unconcentrated when browsing the web in everyday life, mistakes do take place. Therefore it is better and more reliable to detect the different phishing types using an automatic approach.
All presented phishing strategies pursue the objective of obfuscating the real identity of the website and simultaneously trick the recipient into thinking that he visits the original website while he actually visits the forged one. Based on all these phishing strategies, we are able to extract certain lexical features out of a URL. These lexical features are afterwards used as a basis of decision-making in order to decide whether the URL to be examined is a phishing URL or a benign URL. In the following, we listed some examples for lexical features we used. These features can be grouped into count-features, pattern-features, n-gram-features, length-features and binary features:
Count Features
In this group, specific characteristics are counted, e.g:
- Number of dots in the hostname
- Occurrence of the character string 'www' in the hostname
- Number of @-signs in the hostname
Pattern Features
Here, certain patterns are recorded e.g.:
- N-gram features
- Similarity measurements to the most popular websites worldwide
- Change of case
Length Features
This group is dealing with the length of certain properties, e.g.
- Length of the first path segment
- Length of the Top-Level-Domain
- Length of the query
Binary Features
Binary features can be mapped onto pairs like false/true, yes/no, existing/not existing etc.
- IP-address instead of a hostname
We calculated most of the lexical features, for each the hostname, the path, the query and the whole URL. Many dots in the URL are to a certain degree not unusual. When considering dots in the path, many dots point at the existence of hidden folders on the server which could be an evidence of a hacked server. A separate calculation of the features-values for different URL segments is therefore useful.
When looking at the n-gram features, we differentiated between one-grams, two-grams, three-grams and four-grams. Calculating n-grams, the URL, the hostname, the path and the query are devided into segments of one, two, three or four characters. For example, the hostname paypal.com is devided into three-grams of pay, ayp, ypa, pal, al.c, l.c, .co and com. Following this, we calculated the probabilities that these three-grams belong to a phishing and a benign website and added them up for a particular website.
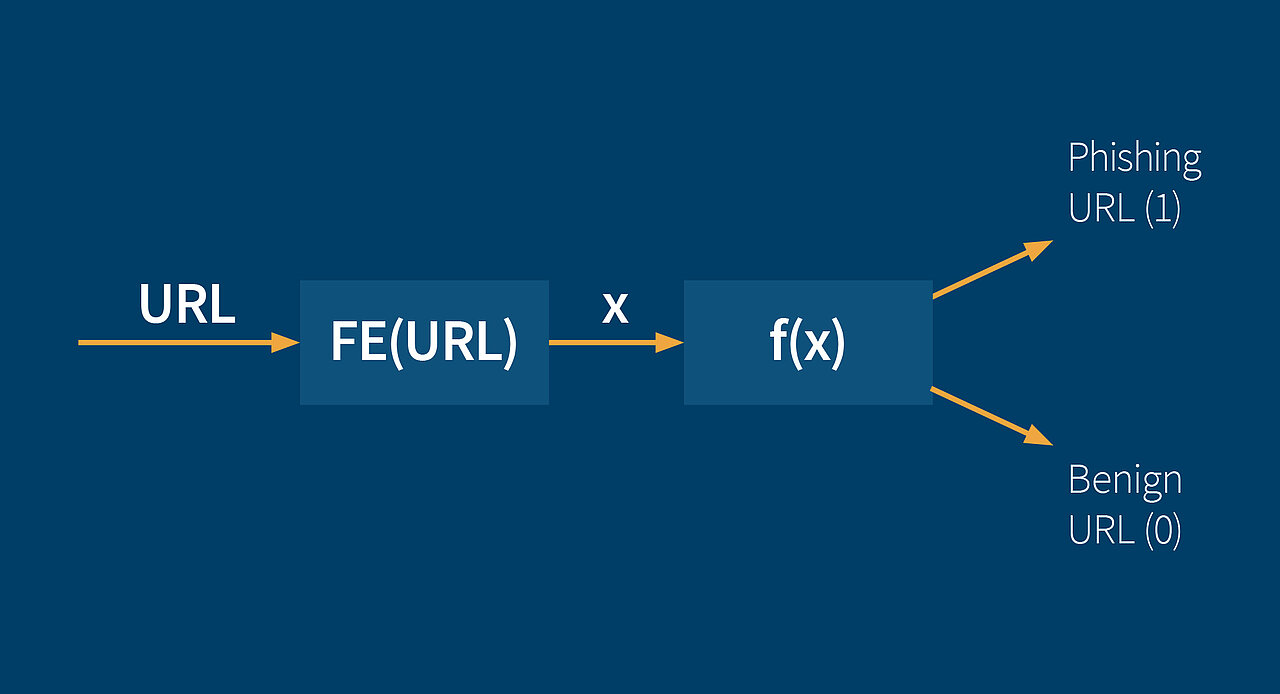
FE = Feature Extraction
These lexical features for a particular URL are taken as input for a function which decides whether the corresponding URL is a phishing URL or a benign URL. At the process of deciding, some of the features are weighted higher than others because they provide more evidence that a URL could be a phishing URL. The function also considers special combinations of lexical features, which highly evidence the presence of a phishing website, if they appear in a URL.
The lexical feature values of known phishing URLs and known benign URLs are now taken as input for four different machine learning algorithms (a neural network, a rainforest algorithm, a decision tree algorithm and a support vector machine algorithm), as well as a machine learning algorithm which combines all of the four mentioned algorithms above. Those machine learning algorithms learn the optimal weighting and the best combinations of lexical feature values in the learning process of the algorithms. Optimal means, that the number of correct classified URLs is maximized when considering these learned optimal combinations of features and the learned optimal weighting of feature values in the function. Determining whether a URL is classified correctly in the learning process is easy because only known phishing and known benign URLs are used. When a machine learning algorithms misclassifies a URL in the learning process, the function re-adjusts the weighting of the lexical features. Broadly speaking, the automatic learning process is the search for good combinations of features and the adjustment of the weights, which determine the impact of the different features in decision-making. After finishing the learning process, we receive a function which classifies unknown URLs with a high degree of correctness by using the calculated weights from the learning process. When looking at the decision tree algorithm, the found rule sets are even visualizable:
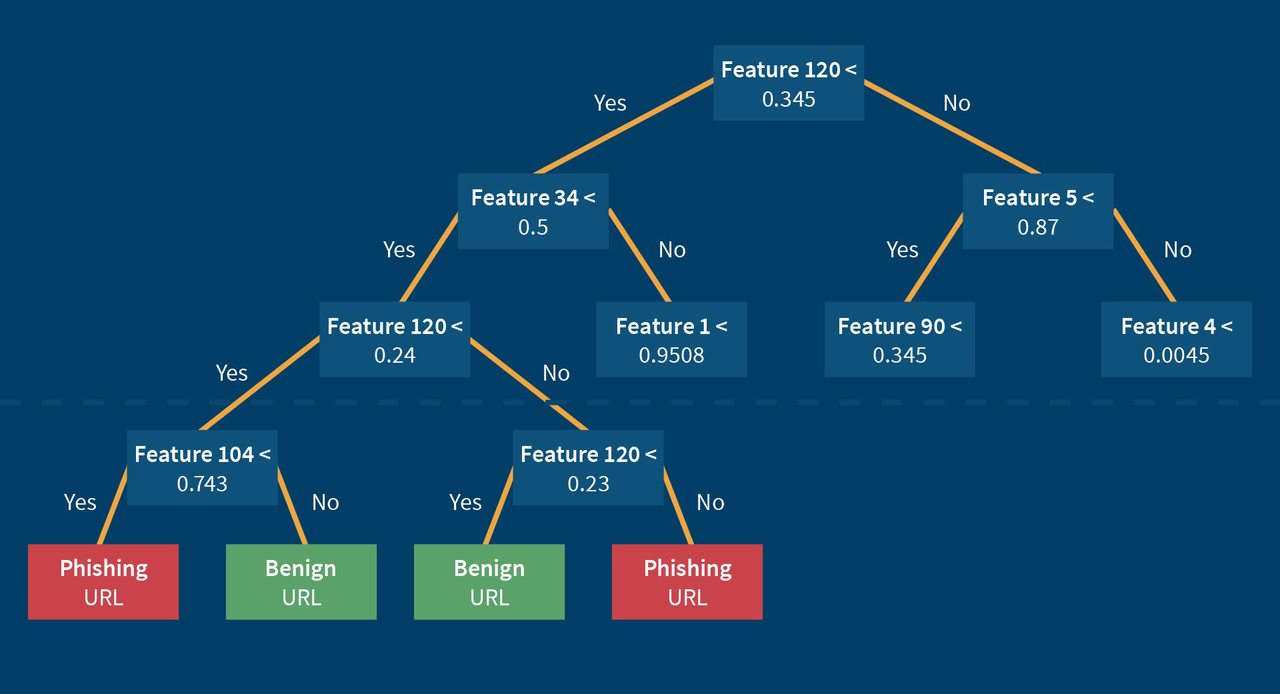
It is possible to visualize a decision tree, which contains a found number of rules, which are used to decide if a website is a phishing website or a benign website. The tree consists of a set of nodes, at which certain questions are asked. In the case of answering a question with “Yes”, one forks to the left, in the case of answering a question with “No”, one forks to the right. Each question has the following structure: Feature x < value ? When starting at the top of the decision tree and answering the questions one after one, we eventually get to a node in which the classification label of the URL to check is contained. In the learning process, the features which divide the learning set of URLs best into the two classes phishing URL and benign URL are arranged at the upper part of the tree. The features which divide the learning set worse or which are based on a complex presorting are arranged in the lower area of the decision tree. As you can see in the figure above, certain features (e.g. feature 120) can be questioned more than once in the path of the decision tree. The best values of the nodes, which determine how to branch, are calculated in the machine learning process. The machine learning of the decision tree algorithm hence optimizes the order and the rule sets in order to classify most URLs of the training set correctly.
With a view of the actual classification, the machine learning algorithms calculate a probability of the URLs being a phishing URL. When classifying URLs normally, all URLs with a calculated probability greater or equal to the threshold of 50% are classified as phishing URLs. But it is also possible to increase the threshold to let's say 90% for example. Then all URLs which are phishing URLs with a probability of 90% or above are classified as phishing URLs. All URLs which contain a probability below 90% are classified as benign. Increasing the threshold, makes sure that the classifier makes less mistakes and classifies less URLs as phishing URLs which are in fact benign (so-called False Positives). Unfortunately due to the increasing of the threshold, the number of URLs which are phishing URLs but are not classified as phishing URLs (so-called False Negatives) is increasing, too. The adjustment of the threshold is therefore a trade-off between false alarms (False Positives) and missed detections (False Negatives). We analysed the four different machine learning algorithms with regard to a good scalability of the false-positive rate to the threshold and got good results when looking at the Rainforest algorithm. These results are illustrated below. As expected, the false-positive rate falls at the cost of the false-negative rate.
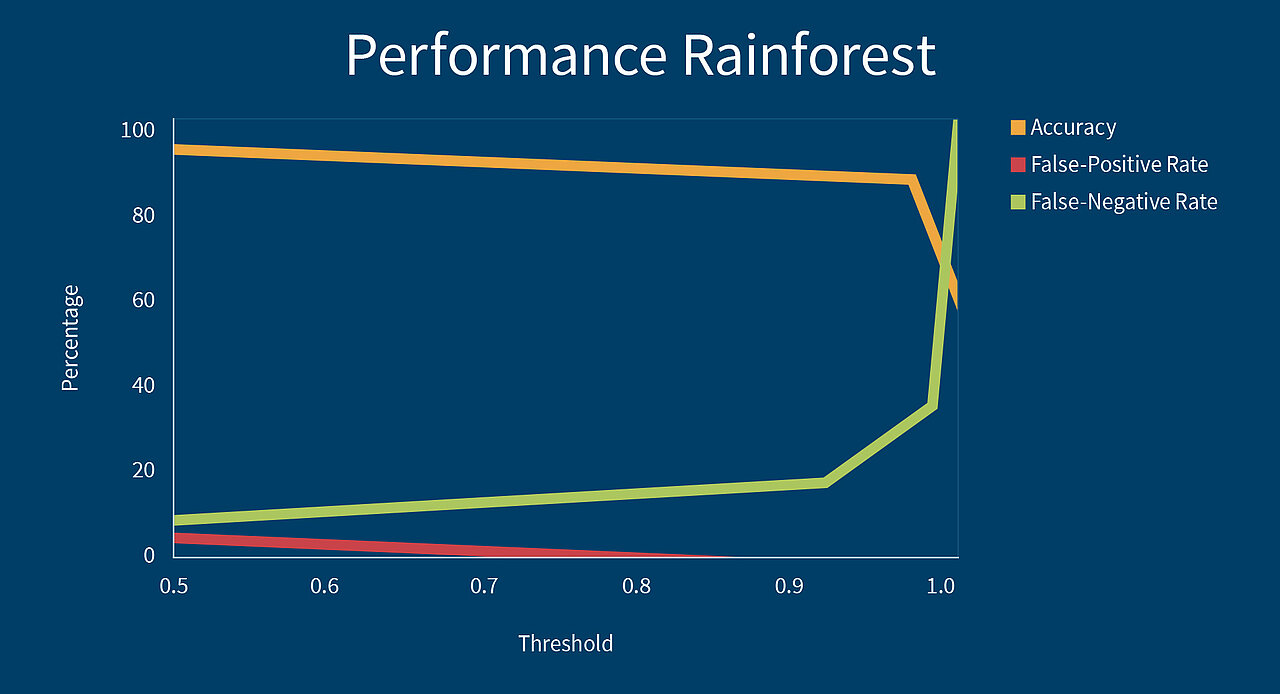
Our achieved accuracy results, as well as the false positive rates and false negative rates are listed in that order in the table below. The achieved results of the four machine learning algorithms Multi Layer Perceptron, Rainforest, Decision Tree, Support Vector Machine and the combined classifier are evaluated with respect to the thresholds 0.5 to 1.0.
The best accuracy is achieved in pursuance of the neural network with an accuracy of 98.08%. This accuracy is achieved while classifying 525.215 unknown URLs. The machine learning algorithms regularly renew the learning set by adding new phishing URLs and subsequently renew their classification function by retraining with this new data. Therefore also new phishing attack patterns invented by cyber criminals are detected and thus can be prevented.

The advantage of machine learning – A smart approach
Common practice to defeat phishing attacks, is the use of blacklists which contain a collection of forbidden phishing URLs. If an internet user visits a website which is contained in the blacklist, access to the website is denied instantly. A significant disadvantage of blacklists is the fact that persons must fall for a phishing attack firstly, and therefore gets damaged before a URL is added to the blacklist. In contrast to this, a machine learning algorithm is capable of classifying unknown URLs and is therefore a proactive approach. Another disadvantage of blacklists is that it is very difficult to keep the blacklists up to date due to the fact that phishing URLs are dynamically adapted by the criminals to evade detection. For this reason it is not possible to discover new attacks using blacklists. 63% of the phishing attacks end after a time period of two hours [4]. Machine learning algorithms have the ability to detect phishing URLs automatically and directly. The classification function is kept up to date while continually retraining and is therefore a countermeasure to protect against new phishing strategies.
Credentials
[1] Lee Neely. Threat Landscape Survey 2017, aug 2017.
[2] Steve Morgan. 2017 Cybercrime Report. Technical report, Cybersecurity Ventures, 2017. URL.
[3] Xi Chen et al., Analyzing the Risk and Financial Impact of Phishing Attacks using Knowledge based Appraoach. 2009. URL.
[4] Lingxi Liu Huajun Huang, Junshan Tan. Countermeasure Techniques for Deceptive Phishing Attack . 2009. URL.